It’s Halloween, and there’s no better time to address one of the trickiest aspects of evaluating a real-world dataset.
Last year was spooky for the healthcare industry, as a series of market-wide events disrupted de-identified patient-level data streams — the lifeblood of our ecosystem. This year, in the shadow of an uncertain data landscape, we’ve seen many companies back in the market pushing out RFPs/RFIs in search of a strong real-world data (RWD) foundation. This search can be arduous and rife with pitfalls. (Tread carefully…there’s zombie data, phantom patients, and haunting duplicates — oh my!)
Recently, one of our industry colleagues penned an article that focused on the importance of transparency when assessing RWD. In a nutshell, the advice was: If your data provider can’t explain the methodology, or tell you in (gory) detail how a particular analysis was run, beware.
This is sound guidance, but I would like to go a step further and address one of the most common miscalculations associated with evaluating RWD: counts.
Counting Claims
Since claims (open, closed, or a combination) are often a foundational component of a real-world dataset, most people in our industry might assume they have a firm understanding of this topic. Yet, rarely a month goes by that I don’t find myself explaining to a prospective customer — who’s accustomed to using counts to assess a dataset — the “tricky” aspects of this seemingly simple task.
To level-set, a claim is, simply put, a request for payment. With the multitude of healthcare entities that may play a role in a single patient’s care, there may be a whole stack of claims even for just one visit.
Each player in the ecosystem can (and most certainly will) make a distinct request for reimbursement. For a single healthcare visit, you may have:
- An institutional claim covering services provided by a facility (e.g., a hospital)
- A professional claim, billed by a provider group, for a physician’s services during the visit
- Lab claims for any bloodwork or genomic testing performed
- Radiology or imaging claims and the interpretation of those scans
- Pharmacy claims for prescriptions filled during or after the visit
- Durable medical equipment to use afterward
Here’s an example of my own recent visit to a primary care provider where I had two different claims for the same visit. Note that both are stamped with the same “Date of visit” of 01/15/2025:
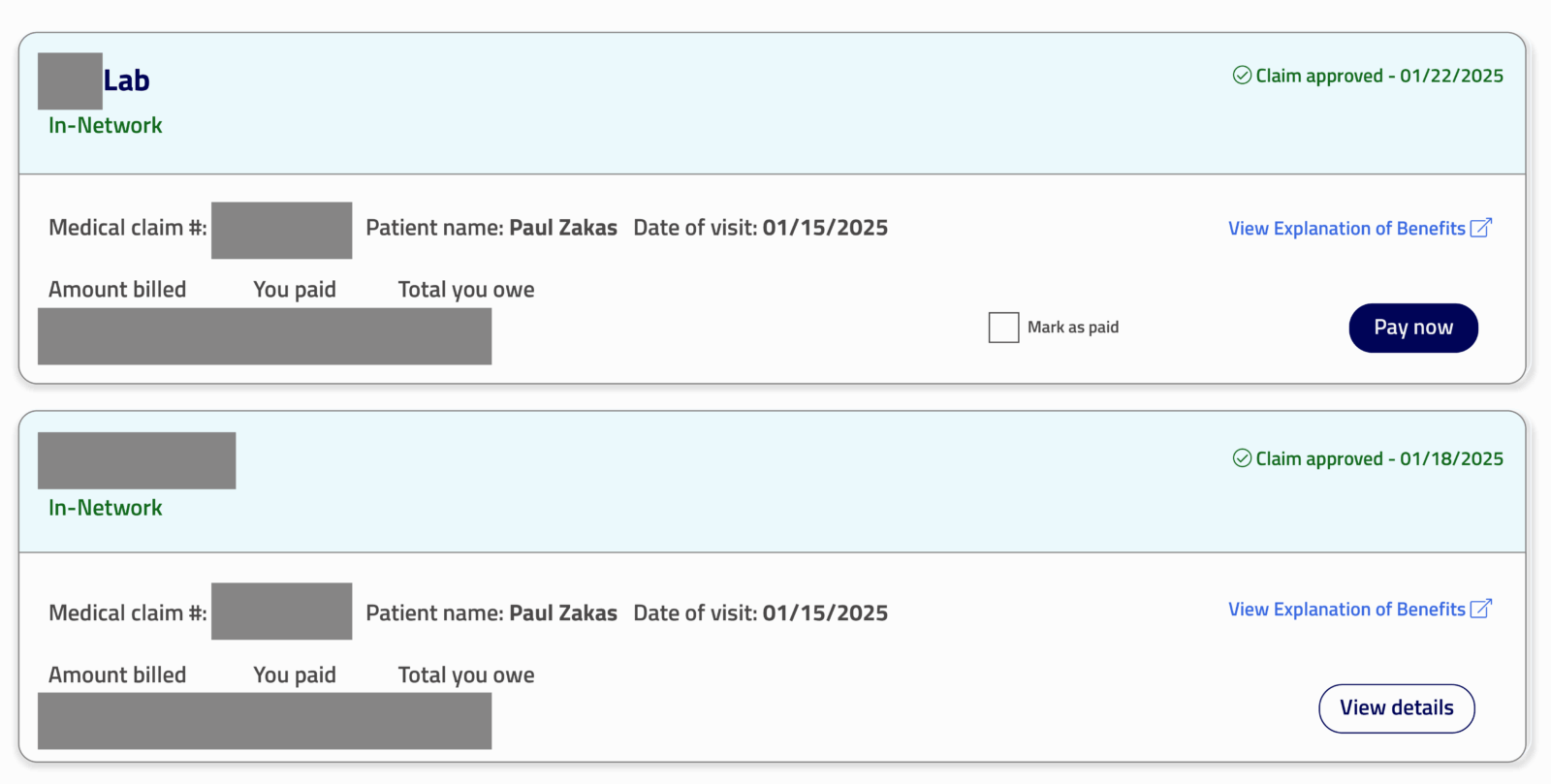
Figure 1: Two different claims for Paul’s primary care visit
How many times did I visit my primary care doctor on January 15th? One. How many claims were generated from that visit? Two. One claim for my provider’s services and another for the lab work.
You can see how a claim count can be misleading without some additional context.
A More Accurate Approach
When analyzing healthcare data, especially in the context of our Life Sciences partners, do we really want to count claims? Why not choose to count something more meaningful, such as the absolute number of procedures that an HCP performed or drug infusions that a patient received?
How can we smooth out this expected variability in the number of claims as compared to real-world events and create the best proxy of a patient encounter between a provider and a patient?
Komodo has standardized on what I believe to be a conservative but reliable approach: counting “patient days.” We use this metric for many analyses that we provide to customers and prospects. For the SQL gurus out there, you would run something like this: select count (distinct patient_id, service_date) as patient_days.

Figure 2: Pembrolizumab infusions, J9271, comparing claim count to patient-days count
As shown in Figure 2, counting claims vs. patient days for pembrolizumab administrations produces roughly the same output, with a variance of ~3-5%. A pembrolizumab infusion is typically a single-day event with one professional claim generated (but, sometimes, an institutional/”I” claim, too!). Because of that, counting patient days reflects a very similar output as claim count.
The same applies for most products that are billed to the pharmacy benefit: Counting paid claims, assuming they’re properly deduplicated in cases of redundancy, will yield a reliable result that should be similar to patient days. Of course, including rejected and reversed claims will drive up the overall numbers beyond the true count of dispensed prescription fills.
However, for certain procedures, the story is very different. In the case of neurostimulators, counting claims produces a 50-60% higher number of implantations as compared to patient days. This is because many of these procedures will produce both an institutional claim and a professional claim for the same patient visit.
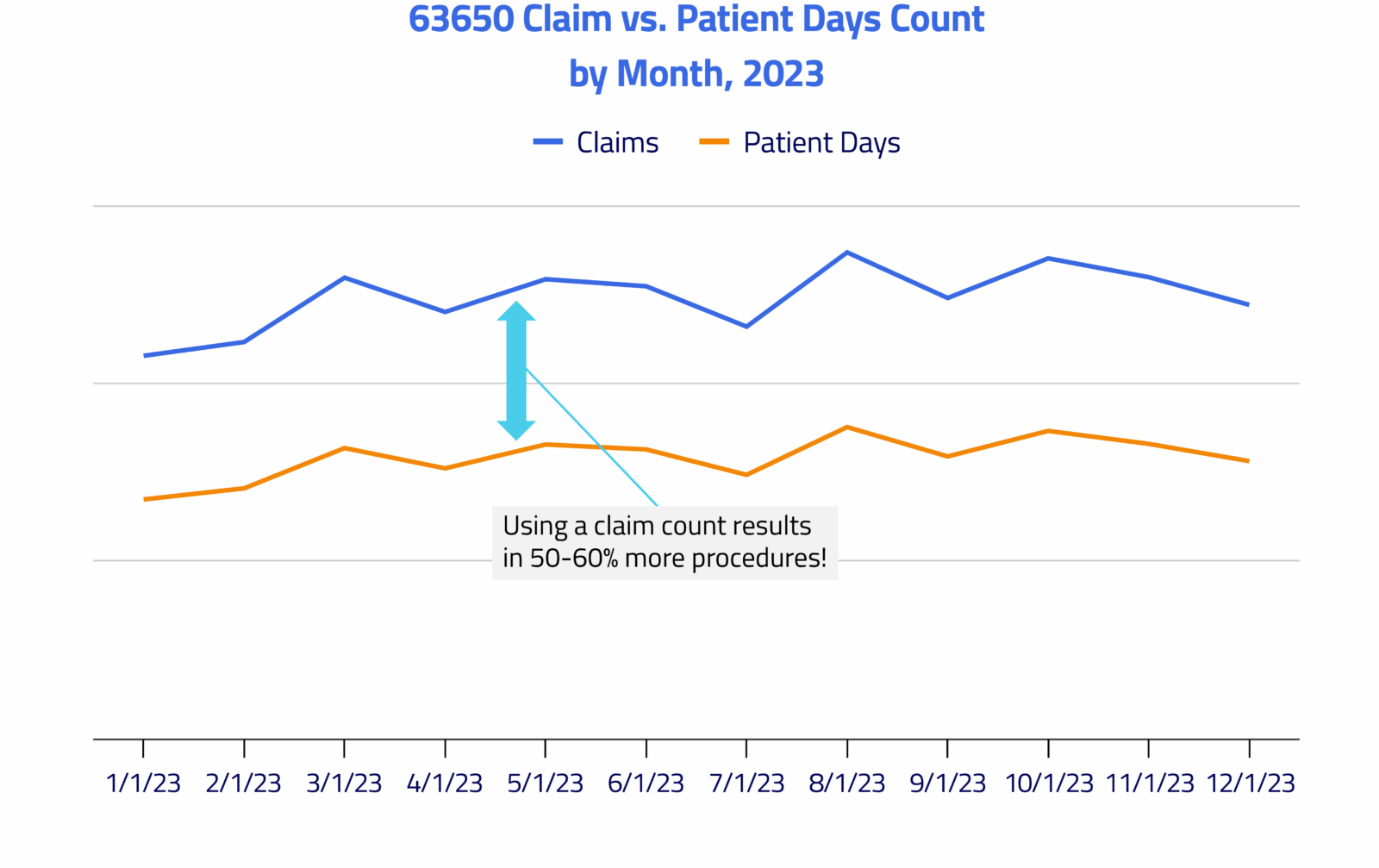
Figure 3: Neurostimulator implantations, CPT code 63650, comparing claim count to patient-days count
Granted, this scenario requires a more complex analytic than either a simple claim count or patient-days count can provide. These procedures often involve a trial period followed by another procedure to do the implant. It warrants using additional business rules, such as counting the patient’s first procedure, or simply counting each patient only once during a particular time span. Any analysis involving inpatient stays requires special methodology as well. But this chart demonstrates the challenges of relying on a claim count alone – you vastly overstate the number of real-world procedures that were performed.
You’ll notice that, in both cases, the patient-days metric produces a lower result than a claim-count metric. However, the patient-days count is a better reflection of the true number of clinical events that occurred.
Speaking of counting…
Another common-but-flawed approach to assessing a dataset is how the number of healthcare providers (HCPs) is determined. Data providers may simply count all NPIs that appear in their datasets without validation, resulting in inflated provider counts due to duplicates, invalid NPIs, and organizational NPIs being counted as individuals.
At Komodo, we integrate NPI registry data, claims activity, and other enrichment to maximize NPI fill rates and ensure invalid identifiers are screened out. This multi-source approach ensures that counted providers actually exist and are responsible for delivering care to patients.
Assessing Data Partners
When evaluating data partners, it’s important to be fully informed about the methodology being used to ensure the most accurate view of the real-world healthcare landscape. In my opinion, this is an area where Komodo’s in-house expertise shines.
In addition to a staff that possesses robust clinical and data experience, we have best-in-class tooling to reliably and repeatedly apply complex business rules such as inclusion/exclusion criteria, offsets (presence or absence of a secondary event in relation to an anchor event), continuous enrollment, and closed baseline/follow-up rules. This combination of expertise and tooling makes Komodo a great partner to our customers across Life Sciences, consultancies, financial services companies, and payers.
Learn more about this topic in our blog post, Are Counts Your Best Bet? And more about assessing data quality in my blog, Is Your Data AI-Grade?
If you want to have a conversation, contact us.
To see more articles like this, follow Komodo Health on X, LinkedIn, or YouTube, and visit our Resources Hub.


